Обеспечение бесперебойной работы. Обеспечение бесперебойного снабжения качественными строительными материалами строительные организации
Нажав на кнопку "Скачать архив", вы скачаете нужный вам файл совершенно бесплатно.
Перед скачиванием данного файла вспомните о тех хороших рефератах, контрольных, курсовых, дипломных работах, статьях и других документах, которые лежат невостребованными в вашем компьютере. Это ваш труд, он должен участвовать в развитии общества и приносить пользу людям. Найдите эти работы и отправьте в базу знаний.
Мы и все студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будем вам очень благодарны.
Чтобы скачать архив с документом, в поле, расположенное ниже, впишите пятизначное число и нажмите кнопку "Скачать архив"
Подобные документы
Социально-экономическое оздоровление финансово-хозяйственной деятельности. Стратегический анализ положения предприятия. Анализ внутренней и внешней среды предприятия. Горизонтальный анализ актива и пассива баланса. Анализ отчета о прибылях и убытках.
курсовая работа , добавлен 22.12.2011
Экономический анализ хозяйственной деятельности. Анализ аналитического баланса, финансовой устойчивости организации, актива и пассива баланса, качества собственного капитала, основных средств, дебиторской и кредиторской задолженности, доходов и расходов.
курсовая работа , добавлен 23.01.2013
Краткая экономическая характеристика и оценка результатов деятельности ООО "Куброс". Состав и структура источников формирования имущества организации. Расчеты с поставщиками и покупателями, организация кассовых операций. Финансовое планирование фирмы.
отчет по практике , добавлен 24.12.2014
Анализ системы управления и оплаты труда. Органы управления предприятием и структура управления персоналом. Организация экономической работы. Основные показатели финансово-хозяйственной деятельности. Анализ доходов и прибыли.
курсовая работа , добавлен 14.09.2006
Оценка структуры и динамики имущества предприятия и источников его формирования. Взаимосвязь показателей актива и пассива баланса. Анализ ликвидности и платежеспособности, показателей финансовой устойчивости и вероятности банкротства предприятия.
курсовая работа , добавлен 02.11.2011
Роль анализа финансово-хозяйственной деятельности в управлении предприятием. Состав и структура баланса ООО "Элегия", показатели оценки его платежеспособности и ликвидности. Разработка мероприятий по стабилизации финансового состояния предприятия.
курсовая работа , добавлен 20.12.2015
Описание деятельности грузового порта. Расчет производительности труда, динамики и структуры актива и пассива баланса, фонда оплаты труда. Оценка показателей платежеспособности предприятия, эффективности использования капитала, кредитоспособности.
курсовая работа , добавлен 09.06.2015
Сущность и методики анализа финансового состояния организации. Характеристика и анализ бухгалтерского баланса ООО "Изумруд", структура его актива и пассива. Оценка отчета о прибылях и убытках и показателей хозяйственно-экономической деятельности.
курсовая работа , добавлен 27.06.2012
Если Вы слепо доверяете
надежности своего "винчестера", то, поверь-
те, наступит день, когда Вы об этом пожалеете. У
любой механической
системы (а жесткий диск таковой и является) есть
свой запас прочно-
сти. Что произойдет после выработки ресурса,
точно никто не пред-
скажет, однако на лучшее можете не рассчитывать:
самая важная для Вас
информация наверняка пропадет безвозвратно. В
Windows NT Server
встроены механизмы, обеспечивающие
отказоустойчивость системы:
для особо надежной работы
с диском, резервного копирования, под-
держки работы с источниками бесперебойного
питания, выбора рабо-
тоспособной конфигурации и восстановления
системы со специально-
го диска. Но как быть, если из строя вышел сам
компьютер? Чтобы это
не отразилось на Вашей работе, рекомендуются кластерные
решения.
Как видите, в системе
достаточно много средств обеспечения беспере-
бойной работы. Возможно, кто-то даже спросит:
зачем так много раз-
ных, на первый взгляд, дублирующих друг друга,
механизмов - ведь это
повышает стоимость системы? Почему раз кластеры
обеспечивают
столь высокую степень надежности, не
использовать их повсеместно?
В таблице 5-1 показаны
различные виды сбоев, которые могут проис-
ходить в сети предприятия, а также методы их
предотвращения или
минимизации неприятных последствий.
| Таблица 5-1 | ||
| Источник сбоя | Кластерное решение | Другие решения |
| Сетевой концентратор | Применимо, если каждый | - |
| из узлов подключен | ||
| к своему концентратору | ||
| Напряжение питания | - | Источник беспере- |
| бойного питания | ||
| Подключение к серверу | Применимо | - |
| Жесткий диск | - | RAID, отказо- |
| устойчивые диски | ||
| Аппаратура сервера | Применимо | - |
| (процессор, память | ||
| и др.) | ||
| Серверное ПО | Применимо | - |
| Маршрутизаторы, | - | Дублирующие |
| выделенные линии и др. | маршруты и линии | |
| Коммутируемые | - | Пулы модемов |
| соединения | ||
| Клиентские | - | Несколько клиентов |
| компьютеры | с одинаковыми | |
| уровнями доступа | ||
Таблица хорошо показывает,
что хотя кластеры и обеспечивают высо-
кую степень надежности сервера, но не являются
панацеей. К тому же
они поддерживаются только версией для
предприятий (Windows NT
Server Enterprise Edition). Требуются дополнительные
механизмы. Рас-
смотрим средства обеспечения бесперебойной
работы, встроенные в
Windows NT Server 5.0.
Средства повышения надежности
работы
с диском
Если Вы регулярно
пользовались такими программами как CHKDSK или
Norton disk Doctor, то наверняка обращали внимание на
иногда обна-
руживаемые на жестких дисках "плохие области" (bad
blocks), которые
эти программы помечают как недоступные. Причин
появления таких
областей несколько, начиная от некачественного
диска и кончая неко-
торыми видами вирусов. Но какова бы ни была
причина, результат все-
гда один - сокращение доступного рабочего
пространства на диске.
Если же Вы своевременно не продиагностировали
диск, то последствия
могут быть еще печальнее: Вы потеряете данные,
записанные на по-
врежденный участок, а, в самом худшем случае,
операционная система
утратит работоспособность. Поэтому, если в Вашем
компьютере толь-
ко один жесткий диск или Вы не используете
технологии, описанные
далее в этой главе, первейшей заботой должна
стать регулярная про-
верка состояния диска.
Замечание.
Современные
компьютерные системы, выпускаемые из-
вестными производителями, зачастую обладают
встроенными средства-
ми контроля за состоянием дисков и оповещения
операционной сис-
темы и администратора о надвигающейся угрозе.
Примером могут слу-
жить компьютеры Compaq Proliant, где о предстоящем крахе
диска из-
вещается не только операционная система, но и
оператор, на пейджер
которого посылается предупреждающий сигнал.
Проверка состояния жесткого диска
Для проверки жесткого
диска используется встроенная утилита CHKDSK,
запускаемая из командной строки. Для поиска
плохих секторов необ-
ходимо запускать ее с ключом /R. При этом, правда,
следует помнить,
что операция может длиться несколько часов. Но
если Вы производите
ее регулярно, то о наличии сбойных секторов
можете косвенно судить
по резко возросшему времени проверки.
CHKDSK [[ path ]filenanie] ],
Указывает диск, который надо проверить;
Filename - указывает файлы
для проверки фрагментации (только на
FAT);
. /F - исправляет ошибки на диске;
. /V - для FAT показывает
полное имя и путь к файлам на диске; для
NTFS - также сообщения об очистке;
. /R - определяет плохие
сектора и восстанавливает читаемую ин-
формацию;
. /L: size - только для NTFS:
устанавливает размер файла журнала в
килобайтах, если размер не указан,
подразумевается активный.
Внимание!
Если во время
работы системы выполнение программы
CHKDSK невозможно (например, на выбранном диске
находится файл
подкачки), Вам будет предложено перенести ее
исполнение на момент
загрузки системы. Если Вы согласитесь, то при
следующей перезагруз-
ке будет выполнена полная проверка диска.
Помимо команды CHKDSK в Windows NT
5.0 для проверки диска име-
ется графическая утилита. Чтобы ее вызвать,
необходимо щелкнуть
правой кнопкой мыши имя диска в папке My Computer и в
появившем-
ся меню выбрать команду Properties.
В
диалоговом окне надо выбрать
вкладку Tools
и щелкнуть кнопку Check Now.
Для полной проверки
диска следует отметить оба флажка: Automatically fix
filesystem
errors
и Scan and attempt recovery of bad sectors.
Диалоговое окно проверки состояния жестких дисков
Чтобы обезопасить себя от
разного рода неприятностей, связанных с
отказами дисковой системы на сервере, лучше
использовать средства,
повышающие надежность их работы. К средствам Windows
NT, обеспе-
чивающих повышенную надежность при работе с
диском, относятся:
зеркализация дисков,
дублирование дисков, чередование дисков с кон-
тролем четности и замена секторов (в "горячем"
режиме).
Технология RAID (избыточный
массив
недорогих дисков)
Средства повышения
надежности работы с дисками имеют промыш-
ленный стандарт и подразделяются на несколько
уровней использова-
ния избыточных массивов недорогих дисков (RAID) (см.
таблицу 5-2).
Каждый из уровней обладает различным сочетанием
производительно-
сти, надежности и стоимости. В Windows NT Server 5.0
обеспечивается
поддержка RAID уровней 0,1 и 5.
Чередование дисков
Этот уровень (RAIDO)
обеспечивает чередование между различными
разделами диска. При этом файл как бы "размазан"
по нескольким
физическим дискам. Данный метод может увеличить
производитель-
ность работы с диском, особенно, когда диски
подключены к разным
контроллерам дисков. Так
как этот подход нс обеспечивает избы точ-
ности, его нельзя назвать в полной мере RAID. При
выходе из строя
любого раздела в массиве все данные будут
потеряны. Для реализации
метода требуется от 2 до 32 дисков. Увеличение
производительности
достигается только при использовании разных
контроллеров диска.

Уровень О: чередование дисков
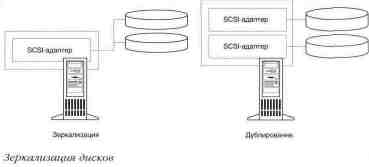
Зеркализация и дублирование дисков
Зеркальная копия диска или раздел создаются средствами RAID уровня 1:
зеркализацией или
дублированием. Зеркальное отражение дисков дей-
ствует на уровне разделов. Любой раздел, включая
загрузочный или
системный, может быть зеркально отражен. Это
простейший метод
повышения надежности работы с диском. Чаше всего,
зеркализация -
самый дорогой метод обеспечения надежности, так
как при нем задей-
ствовано всего лишь 50 процентов объема жесткого
диска. Однако в
большинстве одноранговых или небольших
серверных сетей такой
способ дешев за счет использования всего двух
дисков.
Дублирование дисков -
зеркализация с применением дополнительно-
го адаптера на вторичном дисководе -
обеспечивает отказоустойчи-
вость и при сбое контроллера, и при сбое диска.
Кроме того, дублиро-
вание может повысить производительность.
Подобно зеркализации,
дублирование выполняется на уровне раздела.
Для Windows NT не существует различия между
зеркализацией и дуб-
лированием - вопрос лишь в местонахождении
другого раздела.
Здесь уместно
остановиться и прояснить ситуацию, с которой
доволь-
но часто встречаются администраторы при
зеркализации системного
загрузочного диска. Случается, что при выходе из
строя одного из дис-
ков принимается решение эксплуатировать систему
с другим, остав-
шимся. При этом предполагается, что поскольку
второй диск является
зеркальной копией первого, то никаких
дополнительных мер предпри-
нимать не надо - достаточно просто загрузить
компьютер. Тут-то и
находится камень преткновения: если данный
раздел диска не являет-
Для активизации раздела
надо воспользоваться либо утилитой FDISK,
входящей в поставку любой версии MS-DOS (для
разделов FAT), либо
слепком Disk Administrator.
Чередование дисков с записью кода коррекции
RAID уровня 2 работает так:
блок данных при записи на диск разбива-
ется на несколько частей, каждая из которых
записывается на отдель-
ный диск. Одновременно создается код коррекции,
который также запи-
сывается на разные диски. Потерянные данные
можно восстановить по
коду коррекции с помощью специального
математического алгоритма.
Этот метод требует
выделения на диске больше места для хранения
кода коррекции, чем для информации о четности. В
Windows NT Server
данный метод не используется.
Чередование дисков с записью
кода коррекции
в виде четности
RAID уровня 3 аналогичен
уровню 2 за тем исключением, что код кор-
рекции заменен информацией о четности,
записываемой на один диск.
Таким образом, дисковое пространство
используется лучше. В Windows
NT Server этот уровень также не применяется.
Чередование дисков большими
блоками.
Хранение четности на одном диске
RAID уровня 4 записывает
целые блоки данных на каждый диск в мас-
сиве. Отдельный диск используется для хранения
информации о чет-
ности. Всякий раз при записи блока информация о
четности должна
быть считана, изменена, а затем записана вновь.
Этот метод больше
годится для операций записи больших блоков, чем
для обработки тран-
закций. В Windows NT Server он не применяется.
Чередование дисков с записью
информации
о четности на все диски
RAID уровня 5 применяется в
большинстве современных отказоустой-
чивых систем. От остальных уровней он отличается
тем, что информа-
ция о четности записывается на все диски массива.
При этом данные и
соответствующая им информация о четности всегда
располагаются на
разных дисках. Если один из дисков выходит из
строя, оставшейся
информации достаточно для полного
восстановления данных.
Чередование дисков с
четностью обеспечивает наивысшую производи-
тельность операций чтения. Но при выходе из строя
диска скорость
чтения резко снижается, поскольку нужно
выполнять восстановление
данных. Из-за циркуляции информации о четности
операции записи
требуют в три раза больше памяти по сравнению с
обычной записью.
Этот механизм
поддерживает от 3 до 32 дисков. В набор чередования
могут входить все разделы, кроме загрузочного
(системного).

Уровень 5: чередование диска с четностью
При использовании массива
RAID5 в кластерах в качестве общего ре-
сурса (подробнее об это будет рассказано далее)
наибольшая надеж-
ность и производительность достигается в том
случае, когда каждый из
дисков подключен к своему контроллеру SCSI.

Подключение массива RAID в кластер
Базовые и динамические дисковые тома
В Windows NT 5.0 введены новые
понятия: базового
и динамического
тома.
На базовых дисках можно выполнять
следующие операции:
Создавать и удалять
первичные и расширенные разделы и логичес-
кие диски;
Отмечать раздел как активный;
Удалять наборы томов;
Разбивать зеркализацию в зеркальном наборе;
Восстанавливать зеркальные наборы;
Восстанавливать наборы
дисков с чередованием с сохранением ин-
формации о четности;
Делать диски динамическими;
Превращать тома и разделы в динамические.
Некоторые операции можно
выполнять только
на динамических дис-
ках, а именно:
Создавать и удалять
простые тома, зеркальные тома, тома с чередо-
ванием и RAID-5;
Расширять тома;
Удалять зеркало из зеркального тома;
Исправлять зеркальные тома;
Исправлять тома RAID-5.
Чтобы превратить диск в
динамический, выберите его в слепке консо-
ли управления Disk Management и щелкните правой кнопкой
мыши. В
контекстном меню выберите команду Initialize Disk.
Далее следуйте
указаниям программы.
В первой бета-версии Windows NT
5.0 не поддерживается преобразо-
вание разделов диска в динамические. Эта
возможность будет реализо-
вана во второй бета-версии.
Внимание! Динамические диски не доступны из MS-DOS или Windows.
Замена секторов в "горячем режиме"
В Windows NT Server можно
восстанавливать сектора в процессе рабо-
ты. При форматировании тома файловая система
проверяет все секто-
ра и, обнаружив дефектные, помечает их для
исключения из дальней-
шей работы. Если плохой сектор обнаружен в
процессе записи (чте-
ния), отказоустойчивый драйвер пытается
перенести данные в другой
сектор, а первый - отметить как сбойный. Если
перенос удается, фай-
ловая система не предупреждает о проблеме. Эта
процедура возможна
только на дисках SCSI.


1. Определяет сбойный сектор
2. Перемещает данные в хороший сектор
3. Помечает сбойный сектор
Замена секторов
Исправление ошибок
Описанные возможности
отказоустойчивых конфигураций обеспечи-
ваются при установке в системе драйвера FTDISK. В
общем случае воз-
можности по обнаружению и исправлению дисковых
ошибок опреде-
ляются рядом факторов. В таблице 5-3 перечислены
возможные вари-
анты конфигурации и соответствующие им
возможности "работы над
ошибками".
| Таблица 5-3 | ||
| Описание | Отказоустойчивый том | Обычный том |
| FTDISK установлен; | FTDISK | FTDISK |
| тип жесткого диска | восстанавливает | не восстанавливает |
| SCSI; резервные | данные | данные |
| сектора в наличии | ||
| FTDISK замещает | FTDISK сообщает | |
| плохие сектора | файловой системе | |
| о плохом секторе | ||
| Файловой системе не | NTFS переназначает | |
| известно об ошибке | кластеры; во время | |
| чтения данные теряются | ||
| FTDISK установлен; | FTDISK | FTDISK |
| тип жесткого диска | восстанавливает | не восстанавливает |
| не-SCSI; резервные | данные | данные |
| сектора отсутствуют | ||
| FTDISK посылает | FTDISK сообщает | |
| данные и сообщение | файловой системе | |
| о плохом секторе | о плохом секторе | |
| файловой системе | ||
| NTPS переназначает | NTFS переназначает | |
| кластеры | кластеры; во время | |
| чтения данные теряются | ||
| FTDISK не установлен; | - | Драйвер диска сообщает |
| тип диска любой | файловой системе | |
| о плохом секторе | ||
| NTFS переназначает | ||
| кластеры; во время | ||
| чтения данные теряются | ||
Резервное копирование
Windows NT 5.0, так же, как и
предыдущие версии, обладает встроен-
ной программой резервного копирования. Однако
новая версия отли-
чается рядом функциональных возможностей, среди
которых можно
назвать поддержку различных видов носителей
резервной копии (а не
только магнитной ленты), встроенную возможность
составления рас-
писания резервного копирования,
программу-мастер резервирования
(восстановления), а также новый пользовательский
интерфейс.
Программа Windows NT Backup
Windows NT Backup позволяет
пользователям выполнять резервное
копирование и восстановление данных на
локальный накопитель на
магнитной ленте (стример), на любой жесткий или
гибкий диск, на
устройство хранения на магнитооптических дисках
и, вообще, на лю-
бое устройство хранения информации,
поддерживаемое операционной
системой. Перечислим основные возможности
программы:
Резервное копирование и
восстановление данных, расположенных
на разделах NTFS, FAT и FAT32 как на локальном, так и на
удаленном
компьютере;
Выбор отдельных томов,
каталогов или файлов, подлежащих копи-
рованию (восстановлению), а также просмотр
подробной информа-
ции о файлах;
Выбор носителя, на
который будет выполняться резервное копи-
рование: магнитная лента, диск, гибкий диск,
магнитооптический
носитель и др.;
Выбор дополнительной
проверки правильности записи (восста-
новления);
Обычные операции
резервного копирования: нормальное (normal),
копирование (copy), приращение (incremental), разница
(differen-
tial), ежедневное (daily);
Размещение на одном
носителе нескольких записей и их объедине-
ние или замещение;
Создание командного
файла для автоматизации резервного копиро-
вания;
Планирование операций резервного копирования по времени;
Просмотр полного
каталога резервных копий и выбор файлов и
каталогов, подлежащих восстановлению;
Выбор диска назначения и
каталога, в который будет выполняться
восстановление;
Использование
программы-мастера резервного копирования (вос-
становления) ;
Сохранение информации
об операциях резервирования (восстанов-
ления) в журнале и последующий ее просмотр в Event
Viewer.
Интерфейс программы
Если в предыдущих версиях
Windows NT для запуска программы резерв-
ного копирования требовалось найти
соответствующий значок в груп-
пе средств администрирования, то теперь доступ к
ней осуществляется
подобно тому, как в Windows 95- Щелкните правой
кнопкой мыши зна-
чок, соответствующий жесткому диску, и выберите в
контекстном меню
команду Properties,
а затем в появившемся
диалоговом окне Disk Pro-
perties
- вкладку Tools.
Затем следует
щелкнуть в разделе Backup
кнопку Backup now,
и на экране появится окно
программы резервно-
го копирования.
Внимание!
Для
резервного копирования необходимо, чтобы в сис-
теме был запущен сервис Media support service. В первой
бета-версии
Windows NT 5.0 он не запускается по умолчанию.
Запустите его через
слепок консоли управления Service Management.
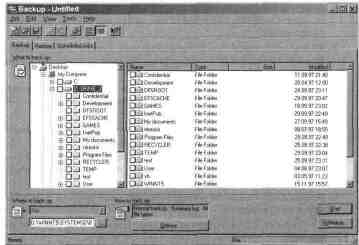
Интерфейс программы Windows NT Backup
В левой части окна Вы
можете видеть дерево устройств Вашего компь-
ютера и сети, к которой он подсоединен. В правой
части показан спи-
сок папок и файлов, находящихся в выбранной Вами
папке. В нижней
части окна можно указать вид носителя, на который
будет выполнять-
ся резервное копирование, тип резервного
копирования, параметры.
Там же находится кнопка Schedule,
с помощью
которой можно про-
смотреть существующее расписание операций
копирования.
Если Вы уверены, что
знаете, какие параметры и как необходимо за-
дать, то можете смело приступать к работе. Если
нет - воспользуйтесь
приглашением, которое появится над описанным
окном программы, и
выберите нужную программу-мастер.
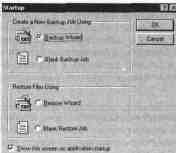
Приглашение начать резервное копирование
Параметры резервного
копирования
(восстановления)
К доступным параметрам
резервного копирования (восстановления)
относятся:
Тип резервного копирования;
Параметры регистрации в журнале;
Файлы, не подлежащие резервированию;
Параметры восстановления.
Для определения этих
параметров либо щелкните кнопку Options
в
нижней части окна программы, либо выберите
одноименную команду
в меню Tools.
На экране появится диалоговое
окно Options.

Диалоговое окно Options, вкладка Backup Type
Вы можете выбрать:
выполнять ли резервное копирование всех отме-
ченных файлов (All selected files)
или только
новых или измененных
(New and changed/lies only).
В первом случае копируются
все выделенные файлы (даже те, которые,
например, уже были скопированы несколько дней
назад и с тех пор не
изменились). Понятно, что время выполнения
резервирования в дан-
ном случае зависит только от общего объема
отмеченных файлов. У Вас
также имеется возможность поставить
переключатель в положение,
предписывающее отмечать модификацию файла (Normal
backup type.
Backup all files. Clear the modified/lag.)
или не делать этого (Copy
backup type. Backup all files. Don t clear the modified flag.).
Второй
тип позволяет значительно сократить время
резервного копирования.
Помимо разностного
резервирования и резервирования с приращени-
ем эффективно ежедневное резервное копирование.
При этом копиру-
ются только файлы,
создание или последняя модификация которых
датированы сегодняшним числом.
Запись в журнал информации
о резервном копировании необходима
для контроля за этой процедурой, отслеживания
сообщений об ошиб-
ках и выяснения их причины. Параметры
регистрации в журнале зада-
ются в том же диалоговом окне Options,
на
вкладке Backup logging.

Диалоговое окно Options, вкладка Backup logging
По умолчанию предлагается
записывать в журнал только наиболее об-
щую информацию (summary details): загрузка ленты, начало
резервно-
го копирования, ошибка доступа к файлу и т. п. Вы
можете либо ука-
зать на необходимость регистрации всех событий
(включая имена
файлов и каталогов), либо отказаться от записи в
журнал вообще. Вот
пример записи без подробностей;
Operation: Backup
Active Device; File
Media Name: "Media created on 15.11.97"
Backup set ft1 on media Ш
Backup Method: Normal
Backup started on 15.11,97 at 16:03.
Backup completed on 15.11.97 at 16:03.
Directories: 2
Files: 5
Bytes: 21,192
Time: 1 second.
Operation: Verify After Backup
Verify Type: Cyclic Redundancy Check
Active Device: File
Active Device: D:\WINNT5\SYSTEM32\Backup.bkf
Backup set HI on media ff1
Backup description: "Set created on 15.11.97 at 16:03"
Verify started on 15.11.97 at 16:03.
Verify completed on 15.11.97 at 16:03.
Time: 2 seconds.
Operation: Restore
Restore started on 15.11.97 at 16:05,
Warning: File New Bitmap Image.bmp was skipped
Warning: File New Rich Text Document, rtf was skipped
Warning: File New Text Document.txt was skipped
Warning: File New WordPad Document.doc was skipped
Warning: File tracking,log was skipped
Restore completed on 15.11.97 at 16:05.
Time: 3 seconds.
Время выполнения
резервного копирования не имеет особого значе-
ния, если объем файлов не велик. Однако при
ежедневном резервиро-
вании файлов и каталогов нескольких
корпоративных серверов, общий
объем дискового пространства, которых может
составлять сотни гига-
байт или даже терабайты, для копирования может не
хватить целой
ночи. Один из способов сокращения времени -
исключение из про-
цесса копирования файлов, которые не
модифицируются вообще, либо
редко и из централизованного источника.
Например, в системных ка-
талогах может быть много файлов шрифтов,
курсоров, картинок и т. п.
Для исключения таких
файлов из списка копируемых, выберите в диа-
логовом окне Options
вкладку Exclude Files
и укажите расширения
всех файлов, для которых не надо делать резервную
копию.

Диалоговое окно Options, вклидка Exclude files
Восстановление файлов не
является какой-то уж очень сложной зада-
чей, но требует внимательного отношения. Не
исключено, что файлы,
хранящиеся на диске, содержат более свежую
информацию, чем запи-
санные в архиве. Восстановив данные из архива на
место существую-
щих, Вы безвозвратно потеряете то, что было
сделано с момента пос-
леднего резервирования.
Именно поэтому не
рекомендуется замещать файлы на диске хранимы-
ми в архиве по умолчанию. У Вас есть выбор:
замещать только те фай-
лы, дата которых старше, чем дата файлов из
архива; или замещать все
файлы без разбора.

Диалоговое окно Options, вкладка Restore options
Выполнение резервного копирования
После определения
параметров резервного копирования можно при-
ступить непосредственно к самой процедуре.
Внимание!
Если Вы
выполняете резервирование в файл, то укажите
имя файла-приемника. Этот файл будет называться в
дальнейшем но-
сителем (media),
несмотря на то, что в физическом
смысле он не яв-
ляется носителем, а сам располагается на
носителе, например, на жес-
тком диске. Термин "носитель" не должен Вас
смущать, когда програм-
ма задает вопрос типа "Заместить все содержимое
носителя?". Речь в
данном случае идет только о файле-приемнике.
Для начала резервного
копирования щелкните кнопку Start
в
програм-
ме Windows NT Backup. Появится диалоговое окно Backup
Informa-
tion,
предлагающее уточнить некоторые
дополнительные параметры.
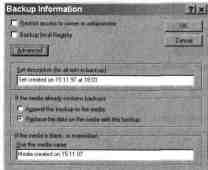
Диалоговое окно Backup Information
Задать параметры Вам помогут следующие элементы окна:
Флажок Restrict access to owner
or administrator
- если он от-
мечен, то доступ к носителю будет запрещен для
владельцев файлов
или администраторов;
Флажок Backup local Registry
- если он отмечен, то будет создана
резервная копия реестра на локальной машине;
Поле Set description
- в
него Вы можете ввести название резерви-
руемой информации; при восстановлении это
название будет пере-
числено в списке доступных наборов;
. фляжок Append this backup to the
media
-
отметив его, Вы укаже-
те программе на необходимость добавления новой
информации к
уже хранимой в архиве;
Флажок Replace the data on the
media with this backup
- отме-
тив его, Вы укажете программе на необходимость
замещения всей
предыдущей информации на носителе новой; в
случае использова-
ния в качестве носителя магнитной ленты будет
создано новое ог-
лавление и данные будут записаны с начала ленты,
в случае исполь-
зования файла на диске - переписано содержимое
файла;
В поле Use this media name следует ввести имя носителя;
Кнопка Advanced
открывает возможность ввести дополнительные
параметры в диалоговом окне Advanced backup options,
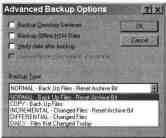
Диалоговое окно Advanced Backup Options
С помощью диалогового окна
Advanced Backup Options
Вы можете
потребовать:
Выполнить резервное копирование службы каталогов;
Выполнить резервное копирование данных иерархичного хранилища;
Проверить данные после резервирования;
Использовать компрессию
на аппаратном уровне (если это допуска-
ет Ваше оборудование);
Выбрать один из описанных ранее типов резервного копирования.
После определения всех
перечисленных параметров начнется процесс
резервного копирования файлов на указанный
носитель.
Планирование резервного копирования
В предыдущих версиях Windows NT
для планирования времени резер-
вного копирования требовалось использовать
системный планировщик
(команда AT). Новая версия имеет встроенный
планировщик, который
позволяет задать начальные день и время
резервирования, указать, яв-
ляется ли данная операция регулярной, если да, то
с какой периодич-
ностью и в течение какого времени должна
выполняться. Все эти пара-
метры задаются для каждого резервного
копирования в диалоговом
окне Scheduled Job Options.

Диалоговое окно Scheduled Job Options
Например, если Вы хотите
выполнять резервное копирование домаш-
них каталогов пользователей каждую ночь, то,
создав соответствующее
задание на резервирование, определите для него:
. Start date - текущее число;
. Start time -
12:00
(надеясь, что в полночь" все пользователи уже
разошлись по домам, где отдыхают, а не работают с
файлами в сво-
их домашних каталогах);
Отметьте флажок Run more then once,
. Frequency - ежедневно (daily), интервал - 1 день.
Также следует указать
учетную запись, имеющую доступ к данному за-
данию на резервное копирование. Эта учетная
запись должна обладать
соответствующей привилегией.

Расписание заданий резервного копирования
Программа указывает полночь "по-американски", то есть в 12.00 AM.
В результате должно
получиться расписание, изображенное на преды-
дущем рисунке. На этом графике также
присутствует еще одно задание,
выполняемое каждый понедельник.
Поддержка источников
бесперебойного питания
Источники бесперебойного
питания (UPS) поддерживают работоспо-
собность системы при сбоях питания за счет
энергии аккумуляторных
батарей. В Windows NT встроен сервис UPS, позволяющий
выполнять
определенные действия в системе при поступлении
сигналов от источ-
ника бесперебойного питания. Кроме встроенного
сервиса, сторонние
производители UPS предлагают дополнительные
продукты, обеспечи-
вающие большую функциональность.
Сервис UPS Windows NT определяет
сбои напряжения питания, предуп-
реждает о них пользователя и корректно заглушает
систему при исто-
щении источника резервного питания.
Настройка параметров
этого сервиса производится в разделе UPS па-
нели управления.

Диалоговое окно
настройки параметров UPS
К настраиваемым параметрам относятся:
Последовательный порт, к
которому подключен источник беспере-
бойного питания;
Сигнал от UPS при сбое напряжения питания;
Предупреждение от UPS при снижении уровня зарядки батарей;
Сигнал от сервиса UPS для
выключения источника бесперебойного
питания;
Командный файл, выполняемый перед выключением компьютера;
Ожидаемое время работы и перезарядки батарей;
Временные интервалы для предупреждающих сообщений.
Сервис UPS должен
использоваться совместно с сервисами Alerter, Mes-
senger и Журналом регистрации. При этом все события,
связанные с
сервисом UPS (например, сбой питания или сбой
подключения источ-
ника бесперебойного питания) будут занесены в
журнал регистрации,
а определенные пользователи будут уведомлены о
них по сети. С по-
мощью параметра Server
на панели управления
можно назначить
пользователей и (или) компьютеры, которые будут
получать эти уве-
домления.
Кластеры серверов
В общем случае кластером
называется группа независимых систем,
работающих как единое целое. Клиент
взаимодействует с кластером как
с одним сервером. Кластеры используются как для
повышения доступ-
ности, так и для наращиваемости.
Доступность.
Когда
система, входящая в кластер выходит из строя,
программное обеспечение кластера распределяет
работу, выполнявшу-
юся этой системой, между другими системами
кластера.
В качестве примера
рассмотрим работу современного супермаркета.
Сердце этого бизнеса - расчетные центры.
Кассовые аппараты долж-
ны быть постоянно подключены к базе данных
магазина, хранящей
информацию о продуктах, кодах, названиях и ценах.
Если связь рвется,
теряется возможность обслуживать клиентов,
ухудшается репутация
торговой организации, падает прибыль.
Кластерная технология
повысит доступность системы. Можно предло-
жить использование двух систем, подключенных к
многопортовому
дисковому массиву, на котором располагается база
данных. В случае
сбоя сервера А резервная система (сервер Б)
автоматически "подхва-
тит" соединение так, что пользователи и не
заметят, что произошел
сбой. Таким образом, комбинация технологий
обеспечения повышен-
ной надежности работы с диском, стандартно
используемых в Windows
NT Server (чередование, дублирование и т. д) с
кластерной технологи-
ей гарантирует доступность системы.
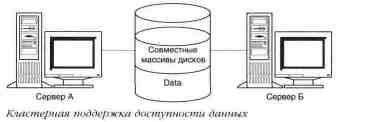
Наращиваемость.
Когда
общая загрузка достигает предела возмож-
ностей систем, составляющих кластер, последний
можно нарастить, до-
бавив дополнительную систему. Ранее для этого
пользователи вынуж-
дены были приобретать дорогостоящие компьютеры,
позволяющие ус-
танавливать дополнительные процессоры, диски и
память. Кластеры
позволяют увеличивать производительность,
просто добавляя новые
системы по мере необходимости.
В качестве примера
наращиваемости рассмотрим ситуацию, типичную
в финансовом бизнесе. Всю полноту
ответственности за работу финан-
совой или банковской сети несет главный
технический специалист. Он
отлично понимает, что малейший сбой системы
повлечет за собой
колоссальные финансовые потери и град упреков в
его адрес. Если же
система работает безукоризненно, то на нее
постепенно будет перекла-
дываться все больше и больше задач, и, несомненно,
однажды возмож-
ности системы будут исчерпаны. Потребуется
разработка и создание
новой системы.
До недавнего времени
подобные соображения приводили к тому, что
технические специалисты крупных банков,
вынужденные заранее ^зак-
ладываться" на огромный рост вычислительных
потребностей, созда-
вали системы на базе больших мэйнфреймов и
мини-ЭВМ.
Кластерная технология на
базе Windows NT Server предоставляет по-
трясающую возможность - отказаться от
дорогостоящего оборудова-
ния и использовать широко распространенную
систему на самых обыч-
ных аппаратных платформах. Мощность кластера
наращивается про-
стым добавлением в него еще одной системы.

Наращиваемость кластеров
Традиционная архитектура
предоставления
высокой доступности
Сегодня для повышения
доступности компьютерных систем использу-
ется несколько подходов. Наиболее типичен метод
дублирования сис-
тем с полностью тиражируемыми компонентами.
Программное обес-
печение постоянно отслеживает состояние
работающей системы, а
вторая система все это время простаивает. В
случае сбоя первой систе-
мы происходит
переключение на вторую. Такой подход, с одной сто-
роны, значительно повышает стоимость
оборудования без повышения
производительности системы в целом, а, с другой -
не гарантирует от
ошибок в приложениях.
Традиционная архитектура
обеспечения
наращиваемости
Для обеспечения
наращиваемости сегодня также применяется
несколь-
ко подходов. Один из способов создания системы с
наращиваемой
производительностью - использование
симметричной мультипроцес-
сорной обработки (SMP). В SMP-системах несколько
процессоров ис-
пользуют общую память и устройства ввода-вывода.
В традиционной
модели, известной как модель совместного
использования памяти,
выполняется одна копия операционной системы, а
процессы приклад-
ных задач работают так, как будто в системе лишь
один процессор. При
запуске в такой системе приложений, не
использующих общие данные,
достигается высокая степень наращиваемости.
Тормозят использование
систем с симметричной обработкой, в основ-
ном, физические ограничения скорости работы шины
и доступа к па-
мяти. По мере увеличения скорости работы
процессоров возрастает их
стоимость. Сегодня пользователь, пожелавший
добавить в конфигура-
цию два-четыре процессора (не говоря уж о
большем числе) должен
заплатить значительную сумму, совершенно
непропорциональную вы-
годе, получаемой от увеличения числа
процессоров.
Архитектура кластера
Кластеры могут иметь
разные формы. Например, в качестве кластера
может выступать несколько компьютеров,
связанных по сети Ethernet.
Пример кластера высокого уровня -
высокопроизводительные много-
процессорные SMP-системы, связанные между собой
высокоскорост-
ной шиной связи и ввода-вывода. В обоих случаях
увеличение вычис-
лительной мощности достигается постепенно,
добавлением очередной
системы. С точки зрения клиента, кластер
представляется в виде одно-
го сервера или образа
одной системы, хотя
реально состоит из не-
скольких компьютеров.
Сегодня в кластерах
используются, в основном, две модели: с общими
дисками и без общих компонентов.
Модель с общими дисками
В модели с общими дисками,
программное обеспечение, исполняемое
на любой из систем, входящих в кластер, имеет
доступ к ресурсам си-
стем кластера. Если двум системам нужны одни и те
же данные, то пос-
ледние либо дважды считываются с диска, либо
копируются с одной си-
стемы на другую. В SMP-системах приложение должно
синхронизовать
и превратить в
последовательный вид доступ к общим данным. Обыч-
но организующую роль при синхронизации играет диспетчер
распре-
деленных блокировок DLM (Distributed Lock Manager).
Сервис DLM
по-
зволяет приложениям отслеживать обращения к
ресурсам кластера.
Если к одному ресурсу обращается более двух
систем одновременно,
то диспетчер распознает и предотвращает
потенциальный конфликт.
Процессы DLM могут приводить к дополнительному
графику сообще-
ний в сети и снизить производительность. Один из
способов избежать
этого эффекта - использование программной
модели без общих ком-
понентов.
Модель без общих компонентов
В модели без общих
компонентов каждая система, входящая в кластер,
владеет подмножеством ресурсов кластера. В
конкретный момент вре-
мени только одна система имеет доступ к
определенному ресурсу, хотя
при сбоях другая динамически определяемая
система может вступить
во владение этим ресурсом. Запросы от клиентов
автоматически пере-
направляются к системам, владеющим необходимым
ресурсом.
Например, если в запросе
клиента содержится обращение к ресурсам,
находящимся во владении нескольких систем, одна
система выбирает-
ся для обслуживания запросов (ее называют
хост-система). Затем эта
система анализирует запрос и передает
подзапросы соответствующим
системам. Те выполняют полученную часть запроса
и возвращают ре-
зультат хост-системе, которая формирует
окончательный результат и
отсылает его клиенту.
Одиночный системный
запрос к хост-системе описывает высокоуров-
невую функцию, порождающую системную активность,
а внутриклас-
терный трафик не генерируется до тех пор, пока не
будет сформиро-
ван конечный результат. Использование
приложения, распределенно-
го между несколькими входящими в кластер
системами, позволяет пре-
одолеть технические ограничения, присущие
одному компьютеру.
Обе модели: и с общим
диском, и без общих компонентов, - могут
использоваться в пределах одного кластера.
Некоторые программы
лучше всего используют возможности кластера в
рамках модели с об-
щим диском. К таким приложениям относятся задачи,
требующие ин-
тенсивного доступа к данным, а также задачи,
которые трудно разде-
лить на части. Приложения, для которых важна
наращиваемость, раци-
ональней исполнять на модели без общих
компонентов.
Серверы кластерных приложений
Итак, кластеры
предоставляют доступность и наращиваемость для
всех
серверных приложений. В свою очередь,
специальные "кластерные"
приложения могут использовать все преимущества
кластеров. Серверы
баз данных могут быть улучшены за счет
добавления либо функций
координации доступа к
общим данным в кластерах с общим диском,
либо функций разделения запросов на более
простые запросы в клас-
терах без общих компонентов. В последних сервер
баз данных сможет
использовать все преимущества разделения данных
путем параллель-
ных запросов. Дополнительно серверные
приложения могут быть рас-
ширены функциями автоматического определения
неработающих ком-
понентов и инициации быстрого восстановления.
Исторически, для создания
кластерных приложений использовались
мониторы обработки транзакций.
Монитор
транзакций отвечает за
перенаправление клиентских запросов к
соответствующим серверам
внутри кластера, распределение запросов между
серверами и коорди-
нацию транзакций между серверами кластера.
Монитор транзакций
также может заниматься балансировкой нагрузки,
автоматическим пе-
реподключением и повторением исполнения запроса
в случае сбоя на
сервере, а также принимать участие в процессе
восстановления после
сбоев.
Модели кластеров Windows NT
Текущая реализация
кластеров для Windows NT поддерживает работу
двух связанных между собой особым образом
серверов. Если на одном
из серверов происходит сбой или он отключается,
то второй начинает
исполнять его функции. Кроме того, кластеризация
обеспечивает ба-
лансировку нагрузки, распределение процессов
между серверами. По
принципу настройки на использование тех или иных
свойств, класте-
ры Windows NT можно разделить на пять моделей:
. модель 1
- высокая
доступность и статическая балансировка на-
грузки;
. модель 2 - "горячий резерв" и максимальная доступность;
. модель 3 - частичная кластеризация;
. модель 4 - только виртуальный сервер (без переключения);
. модель 5 - гибридная.
Давайте вкратце рассмотрим эти модели.
Модель 1: высокая доступность и
статическая
балансировка нагрузки
В этой модели
обеспечивается высокая доступность; а также
произво-
дительность: приемлемая - при одном
неработающем узле, и высо-
кая - при обоих работающих; а также максимальное
использование
аппаратных ресурсов.
Каждый их двух узлов
предоставляет в сеть свой собственный набор
ресурсов в виде виртуальных серверов, к которым
имеют доступ кли-
енты. Производительность каждого из узлов
подобрана таким образом,
что обеспечивает оптимальную
производительность для ресурсов, но
только до тех пор, пока оба
узла работоспособны. При сбое одного
сервера исполнение всех кластерных ресурсов
переключается на дру-
гой, производительность резко понижается, однако
все ресурсы по-
прежнему доступны для клиентов.
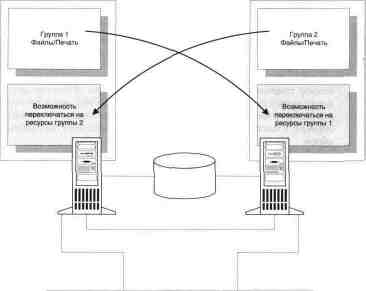
Конфигурация модели 1
Например, эта модель может
применяться при совместном использо-
вании файлов и принтеров. На каждом из узлов
создаются независи-
мые группы с файловыми и принтерными ресурсами.
При сбое одного
из узлов все управление его ресурсами берет на
себя оставшийся. Пос-
ле восстановления узел возвращает себе свою
часть работы, В резуль-
тате клиенты имеют постоянный доступ как ко всем
файловым ресур-
сам кластера, так и ко всем очередям печати.
Рассмотрим другой пример
использования этой модели. Допустим, на
предприятии имеется почтовый сервер, на котором
установлен Mic-
rosoft Exchange. В пиковые моменты нагрузки сервер не
справляется и
отключается. Поскольку почта должна
функционировать непрерывно,
можно предложить следующее решение. Сервер, на
котором исполня-
ется Microsoft Exchange, объединяется в кластер с
сервером, на кото-
ром в нормальном режиме работает приложение
доступа к данным. В
момент сбоя почтового сервера его роль временно
принимает на себя
второй сервер кластера. Но, подчеркиваю, это лишь
временно, и сразу
после перезагрузки основного почтового сервера
вся работа по обра-
ботке почты вновь
передается ему. Аналогично может выполняться пе-
реключение программы работы с базами данных.
Модель 2: "горячий резерв"
и максимальная доступность
При такой модели
обеспечивается максимальная доступность и
произ-
водительность, но за счет вложений в
оборудование, которое большую
часть времени простаивает. Один из узлов
кластера, называемый пер-
вичным,
обслуживает всех клиентов, в то время
как второй использует-
ся в качестве "горячего резерва".
Когда происходит сбой
первичного узла, второй незамедлительно за-
пускает сервисы, исполнявшиеся на первом, и
обеспечивает при этом
производительность, максимально близкую к
производительности пер-
вичного узла.
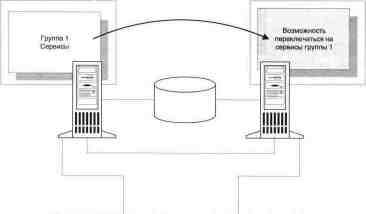
Модель с "горячим резервированием"
Эта модель наилучшим
образом подходит для наиболее важных для
организации приложений. Например, это может быть
сервер Web, об-
служивающий тысячи клиентов и предоставляющий
доступ к важней-
шей информации. В таком случае стоимость узла,
дежурящего в режи-
ме "горячего резерва", все равно значительно
ниже потерь, возможных
в случае прекращения доступа к данным.
Модель 3: частичная кластеризация
Данная модель позволяет
использовать на серверах, составляющих кла-
стер, приложения, для которых не будет
выполняться переключение в
случае сбоя. Ресурсы таких приложений
располагаются не на общем, а
на локальном диске
сервера. В случае сбоя сервера эти приложения
становятся недоступными.

Модель частичной кластеризации
Эта модель подходит, если
приложения, работающие на одном из сер-
веров, входящем в кластер, используются не часто
и их постоянная
доступность не столь необходима. Например, это
может быть какое-
либо бухгалтерское приложение или расчетная
задача.
Иногда случается, что
модель переключения, обеспечиваемая Microsoft
Cluster Server, не годится для некоторых приложений.
(Например, при
исполнении расчетной задачи переключение с узла
на узел все равно
прервет процесс вычислений). Для таких
приложений необходимы
иные, специфичные механизмы обеспечения
бесперебойной работы.
Модель 4: только виртуальный
сервер
(без переключения)
Строго говоря, эту модель
трудно назвать кластером. В ней использу-
ется только один сервер, переключение которого в
случае сбоя не вы-
полняется.
С другой стороны, все
ресурсы организованы так, что для пользовате-
ля они предстают в виде ресурсов разных
виртуальных серверов. По-
этому вместо поиска нужных ресурсов на различных
серверах в сети
пользователь осуществляет доступ только к
одному.
В случае сбоя сервера
программное обеспечение кластера запускает
необходимые сервисы в указанном порядке сразу
после перезагрузки.
В будущем такой узел может
быть соединен с другим для организации
полноценного кластера.
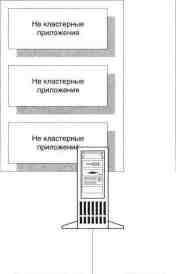
Модель с одним виртуальным сервером
Модель 5: гибридное решение
Последняя модель - гибрид
предыдущих. В самом деле, при достаточ-
ном запасе мощности можно использовать
преимущества всех моделей
в одной и обеспечить самые разные сценарии
переключения в случае
сбоя.
На рисунке показан
возможный пример гибридного решения, в кото-
ром на обоих узлах кластера имеются
переключаемые ресурсы, непе-
реключаемые приложения и сервисы, а также
виртуальные серверы.

Гибридное решение
Установка Microsoft Cluster Server
Установить программное
обеспечение поддержки кластеризации очень
просто. Выполнение программы установки на двух
компьютерах зай-
мет у Вас не более 10 минут. Однако, как и в любом
деле, лучше семь
раз отмерить, и один раз - отрезать. В данном
случае это означает, что
перед установкой ПО необходимо тщательно
соблюсти некоторые
начальные условия и сконфигурировать серверы
соответствующим
образом.
Прежде чем начать
Для установки MSCS (Microsoft Cluster
Server) необходимо иметь следу-
ющее оборудование.
1. Два компьютера
произвольной конфигурации. Характеристики
компьютеров могут различаться. Например, один
имеет процессор
Pentium Pro с тактовой частотой
200 Мгц, объем ОЗУ - 256Мб, встро-
енный жесткий диск объемом 2 Гб. Второй -
процессор Pentium II с
тактовой частотой 233 Мгц, объем ОЗУ б4Мб и
встроенный жесткий
диск объемом 1 Гб. Разброс характеристик
определяется используе-
мой Вами моделью: от практически идентичных (для
режима "горя-
чего резервирования") до совершенно различных
(для режима час-
тичной кластеризации).
2. В каждом компьютере
должно быть не менее одного SCSI-адап-
тера,
к которому будут подключаться общие
диски. К этим адапте-
рам применяется одно жесткое требование: они
должны обеспечи-
вать такой режим работы, который позволяет не
инициализировать
шину при перезагрузке. В ряде случаев с этой
целью может понадо-
биться отключить BIOS адаптера.
Другим требованием
является то, что SCSI ID одного из компьюте-
ров должен быть обязательно равен шести, а
другого - семи.
Отдельного рассмотрения
заслуживает вопрос терминирования
шины. Оно должно выполняться таким образом, чтобы
никак не
зависеть от работоспособности любого из
компьютеров. По этой
причине внутренние терминаторы SCSI-адаптера не
подходят. Тер-
минаторы должны находиться снаружи. Можно
предложить два ва-
рианта с расположением общих дисков:
между серверами;
на одном конце.
В первом случае на обоих
концах шины подключение к серверам
должно осуществляться с помощью так называемых
Y-кабелей.

Связь с промежуточным расположением устройств хранения
Во втором случае два
сервера связаны между собой так, что сервер,
более удаленный от общих дисков, подключается с
помощью Y-ка-
беля, а дисковый накопитель - с помощью обычного
кабеля, но
имеет либо внутреннюю терминацию, либо
специальный разъем для
подключения внешнего терминатора.

Связь серверов с расположением общих дисков на одном конце
3. Не меыее 2 сетевых плат
в каждом компьютере. Узлы в кластере
должны быть связаны между собой надежным
каналом, называемым
интерконнектом (interconnect).
По этому каналу они
обменивают-
ся друг с другом информацией о своем состоянии.
Предположим, в
качестве такого канала используется та же самая
сетевая плата, что
и для доступа к ресурсам кластера. В этом случае
велика вероятность,
что в моменты загрузки сети будет происходить
ложное срабатыва-
ние процедуры переключения. При обоих
работоспособных серве-
рах информация об их состоянии просто не будет
доходить от од-
ного к другому. В результате оба сервера
инициируют процесс пе-
реключения, что, вполне вероятно, приведет к сбою
системы.
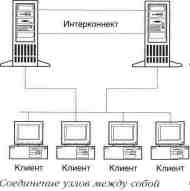
Именно поэтому
рекомендуется использовать для интерконнекта
отдельный сетевой канал. Для более высокой
надежности желатель-
но организовать несколько таких каналов. В любом
случае, считай-
те, что для Вас дороже: стоимость потерянной на
время информа-
ции или стоимость нескольких сетевых плат.
Взаимодействие между
кластерами осуществляется по протоколу
TCP/IP. Поэтому Вам понадобится назначить адреса
для сетевых карт
интерконнекта. Для этой цели можно использовать
специальные
зарезервированные адреса:
10.0.0.1 - 10.255.255.254;
172.16.0.1 - 172.31.255.254;
192.168.0.1 - 192.168.255-254.
4. Общим дискам в серверах
должны быть присвоены одинаковые
буквы.
Например, если в одном из серверов
локальные диски име-
ют буквы С, D и Е, а в другом - С, D, Е, F и G, то первый
общий диск
в обеих системах должен быть диском Н.
Внимание! Все общие диски должны иметь формат NTFS.
Присвоение букв дискам
выполняется по очереди. Сначала загружа-
ется один сервер, а второй остается выключенным.
С помощью слеп-
ка Disk Management назначается нужная буква. После этого
первый
сервер выключается, загружается второй и
назначается та же самая
буква для выбранного раздела диска.
После того, как выполнены
все перечисленные условия, можно устанав-
ливать ПО MSCS.
Процедура установки
Процедура проста: сначала
выполняют установку на одном узле, а по
ее завершении - на втором. Для установки
необходимо зарегистриро-
ваться в домене с административными правами.
Устанавливать ПО надо на
локальный, а не на общий диск. В процессе
установки ПО на первый сервер надо указать имя,
под которым клас-
тер будет доступен для клиентов, имена дисков,
предназначаемых для
использования в качестве общих ресурсов, сетевые
карты и их назна-
чение (для связи с клиентами, для интерконнекта
или для того и друго-
го), адреса IP и маску.
Процедура установки на
второй сервер аналогична, за тем исключени-
ем, что вместо формирования нового кластера надо
подключиться к
уже существующему.
Администрирование кластера
Для администрирования
кластера используется программа Cluster Admi-
nistrator. Она может быть установлена как на любом из
узлов, входящих
в кластер, так и на произвольной рабочей станции.
Интерфейс программы
весьма напоминает интерфейс консоли управ-
ления с загруженным слепком, однако теперь
администратор класте-
ров не является слепком ММС.

Окно Cluster Administrator
Окно состоит из двух
частей. В левой части в виде древовидной струк-
туры представлены элементы кластера: группы,
доступные ресурсы,
сетевые интерфейсы, узлы и т. д. В правой -
содержимое той или иной
ветви древовидной структуры кластера.
На панели инструментов
есть кнопка, позволяющая подключиться к
любому кластеру для управления им. С помощью
администратора кла-
стера можно выполнять следующие операции:
Создавать новый ресурс;
Создавать и модифицировать группу ресурсов кластера;
Управлять сетевыми интерфейсами;
Управлять ресурсами каждого из узлов в отдельности;
Имитировать сбой в работе ресурса;
Останавливать работу отдельных групп;
Перемещать ресурсы между группами.
Большинство функций
выполняется с помощью программ-мастеров.
Поскольку данная книга не ставит перед собой
задачу подменить доку-
ментацию, мы лишь кратко рассмотрим некоторые
операции.
Создание новой группы ресурсов
Создавая новую группу
ресурсов, необходимо помимо ее имени, ука-
зать предпочтительного владельца. Выбор зависит
от типа используе-
мой модели кластера. Добиваясь высокой
доступности, можно указать
в качестве владельцев оба узла. При обеспечении
"горячего резерва"
предпочтительным владельцем должен стать
основной узел.
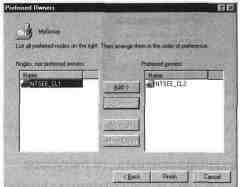
Назначение предпочтительного владельца группы ресурсов
Создание нового ресурса
В Microsoft Cluster Server можно
создавать ресурсы одного из следую-
щих типов:
Координатор распределенных транзакций;
Совместно используемый файловый ресурс;
Приложение общего вида;
Сервис общего вида;
Виртуальный корень Internet Information Server;
Адрес IP;
Сервер очередей (Microsoft Message Queue Server);
Сетевое имя;
Физический диск;
Спулер печати;
Сервис таймера.
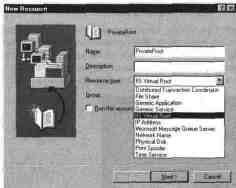
Добавление нового ресурса
Например, если Вы хотите
добавить новый виртуальный корень для
своего сервера Web, то необходимо создать ресурс
типа US Virtual Root.
Определение взаимозависимости ресурсов
Очевидно, что ресурсы
кластера не могут запускаться в произвольном
порядке. Те сервисы, от которых зависит работа
остальных, должны
стартовать раньше.

Определение зависимости загрузки ресурсов
Так, прежде чем сделать
виртуальный корень сервера Web доступным
для пользователей, необходимо выполнить, по
крайней мере, две опе-
рации: определить диск, на котором физически
располагается каталог,
являющийся виртуальным корнем, и назначить адрес
IP. Соответствен-
но эти два ресурса необходимо назначить
определяющими для вирту-
ального сервера.
Определение свойств ресурса
Наконец, после того, как
задана последовательность загрузки ресурсов,
можно определить свойства вновь создаваемого
ресурса. Окно свойств
существенно различается в зависимости от типа
ресурса. Например, на
рисунке показано определение параметров
виртуального корня серве-
ра Web. Для него указывается полный путь на диске,
имя, под которым
он будет доступен для клиентов, а также тип
доступа.

Определение специфичных параметров ресурса
Редактирование свойств ресурсов
Свойства любого ресурса
можно отредактировать. Для этого необходи-
мо щелкнуть имя ресурса правой кнопкой мыши и в
контекстном меню
выбрать команду Properties.
Появится
диалоговое окно, подобное
изображенному на рисунке.

Модификация свойств f)ecvl)ca
В этом диалоговом окне можно изменить следующие параметры:
Имя и описание ресурса;
Возможных владельцев ресурса (на уровне серверов);
Последовательность
загрузки сервисов, влияющих на работу редак-
тируемого ресурса;
Параметры перезапуска ресурса в случае сбоя;
Интервалы опроса;
Командную строку и параметры запуска.
Проверка работоспособности
Для проверки
работоспособности созданной группы ресурсов в
адми-
нистраторе кластера предусмотрена возможность
имитации сбоя. На-
пример, для проверки работоспособности
виртуального корня серве-
ра Web его исполнение переносится на другой узел
командой меню.
В течение последующих
минут администратор увидит в окне Cluster
Administrator,
как система распознает остановку
сервиса, иницииру-
ет его запуск на другом узле и, после запуска всех
определяющих сер-
висов, запускает выбранный ресурс. Клиенты
заметят лишь небольшую
(одну-две минуты) задержку.
Хотя параметры
перезапуска можно редактировать, не
рекомендуется
уменьшать время проверки работоспособности, так
как небольшие
паузы в работе могут быть расценены как сбой
кластера.
Заключение
Windows NT 5.0 унаследовала от
предыдущих версий все возможности
обеспечения бесперебойной работы. Средства
поддержки отказоустой-
чивых дисковых томов, поддержка источников
бесперебойного пита-
ния, улучшенная версия программы резервного
копирования удачно
дополняются кластерными технологиями.
Несомненно, что
перечисленные возможности в совокупности с под-
держкой аппаратных средств отказоустойчивости
позволяют говорить
о Windows NT Server 5.0 как о серверной операционной
системе, впол-
не способной удовлетворить потребности
предприятий, где требуется
высокий уровень надежности.
В начале этого года на северо-востоке США бушевали невиданной силы грозы. Они нарушили электроснабжение местного call-центра службы спасения 911, и в сервисном отделе фирмы Liebert, входящей в состав компании Emerson Network Power, раздался звонок с просьбой о помощи. Батареи ИБП в ЦОДе вышли из строя, и, учитывая специфику работы call-центра, было необходимо срочно обеспечить его функционирование.
Мы быстро отреагировали, и вскоре call-центр вновь нормально работал. Изучив причины случившегося отказа, представители вендора вместе с руководством call-центра вынуждены были признать, что не была внедрена программа сервисного обслуживания (которая обычно включает профилактическое техобслуживание, регулярные проверки и мониторинг). Если бы в ЦОДе действовала такая программа, то отказа батарей можно было бы избежать.
Подобные случаи постоянно напоминают о том, сколь необходима всеобъемлющая программа профилактического техобслуживания. В сегодняшних быстро меняющихся условиях с неуклонно растущей ролью ЦОДов такая программа совершенно необходима для обеспечения бесперебойной работы.
Перемены повсюду
В условиях постоянно развивающихся ИТ одна из главных трудностей, с которой сталкиваются менеджеры ЦОДов, — это не отстать от перемен. Ушли в прошлое те времена, когда достаточно было иметь небольшую распределенную сеть, охватывающую несколько близлежащих узлов. Сегодня ЦОДов стало меньше, но они теперь гораздо крупнее, более централизованны и берут на себя громадные объемы вычислений.
Также ИТ-инфраструктура многих организаций развилась во взаимозависимую, критически важную сеть, охватывающую данные, приложения, хранение, серверы и собственно сетевое оборудование. Отказ питания в любой точке этой сети может нарушить работу всей организации и негативно сказаться на ее бизнесе.
Ввиду этих перемен очень важно, чтобы организации имели надежные планы профилактического техобслуживания в своих ЦОДах, а также знающих специалистов, что называется, под рукой. Переходя на новое оборудование и осуществляя централизацию своих ЦОДов, организации не должны упускать из вида, что столь же важно иметь надежную инфраструктуру питания и охлаждения, чтобы гарантировать постоянную доступность ИТ.
Слишком часто можно наблюдать такую картину: ИТ-директор решает купить новые серверы для организации, но когда они уже готовятся к установке, менеджер ЦОДа обнаруживает, что не было проведено никакой оценки того, насколько имеющаяся инфраструктура питания и охлаждения соответствует новым требованиям. Профессиональная оценка может определить, например, что на одной из критически важных линий не хватает мощности резервного питания для поддержки новых серверов.
Кроме того, тепловой анализ может показать, что одна из стоек охлаждается недостаточно хорошо. Если бы ИТ-директор и менеджер ЦОДа нашли время встретиться до того, как начинать внедрение, и обратились бы к сервисной организации, чтобы точно определить будущие требования к системам питания и охлаждения, то в смету уже были бы заложены дополнительные капиталовложения и оптимизация этих систем, дабы не создать риска возможных отказов.
Главное — гарантировать безотказность
При наличии хорошо согласованной программы сервисного техобслуживания в рамках всей организации риск нарушения питания, будь то стихийное бедствие или плановый апгрейд оборудования, можно свести к минимуму. ИТ-менеджеры рассчитывают сегодня на 100%-ный уровень готовности. Но как его достичь без всеобъемлющей программы профилактического техобслуживания? Как и ваш автомобиль, ЦОДы также должны быть надежны, им необходим регулярный “техосмотр”, чтобы надежность могла быть гарантирована.
Кроме того, бесперебойность работы зависит от знания менеджерами ЦОДов потенциальных опасностей и их способности разработать план вместе со специалистом по техобслуживанию, чтобы свести к минимуму риск отказа критически важных функций. Хорошо подготовленная организация будет иметь минимум нарушений в работе и будет чувствовать себя уверенно, даже если что-то случится.
Сегодня, как никогда, организации зависят от своей ИТ-инфраструктуры, от ее надежной работы, и не стоит экономить на том, чтобы построить тесные, доверительные отношения с поставщиком сервисных услуг. Опытный специалист поможет разработать и внедрить сильный план обеспечения бесперебойности бизнеса, который гарантирует не только оперативную готовность вашей ИТ-инфраструктуры, но будет охватывать весь жизненный цикл ЦОДа. Но программа, созданная сегодня, может перестать соответствовать требованиям через несколько лет, поэтому необходимо постоянно ее корректировать и развивать. Без такой всеобъемлющей, постоянно развивающейся программы организации подвергают себя риску потерять доходы и вызвать неудовлетворенность заказчиков.
Кроме того, организация может понести незапланированные расходы на ремонт и замену оборудования. Конечно, всё это трудно вписать в ограниченный ИТ-бюджет, но без необходимого техобслуживания затраты могут оказаться еще выше и будут к тому же неожиданными для организации.
Ваши требования к поставщику техобслуживания
Выбирая поставщика услуг техобслуживания, ищите тех, кто инвестирует в лучший инструментарий и знающий персонал. Один из верных способов свести к минимуму риск отказов питания — это внедрить всеобъемлющую программу планово-предупредительного техобслуживания с участием обученных вендором специалистов. Вы можете смело полагаться на поставщиков техобслуживания, если они:
- могут гарантировать быстрый отклик по вашему вызову;
- имеют опыт работы с установленным у вас оборудованием (чтобы восстановить его работоспособность с первого раза);
- гарантируют наличие запчастей;
- постоянно обучают своих инженеров, повышая их квалификацию, и снабжают их всеми новейшими приборами и средствами, необходимыми для работы;
- имеют репутацию надежного и соблюдающего нормативные требования партнера;
- способны дать вам целостную картину состояния вашего ЦОДа благодаря широте своего предложения.
Сегодня многие ведущие поставщики услуг технического обслуживания имеют новейшее тестовое оборудование и прекрасно обученных специалистов, так что проблемы часто можно разрешить, даже не посылая специалиста к заказчику. Имея хорошо спланированную стратегию, менеджеры ЦОДов могут смело рассчитывать на специалистов техобслуживания, которые решат их проблемы без простоев и снижения уровня готовности всех систем.
Заключение
Мы живем в эпоху перемен, в том числе внутри ЦОДов. Перемены неизбежны. ИТ меняются ежечасно, стремясь к совершенству, и это следует принять как данность. Всеобъемлющая программа профилактического техобслуживания, которая включает превентивные меры, регулярные проверки и мониторинг оборудования, просто необходима.
Отказ в call-центре, о котором мы рассказали в начале, был быстро ликвидирован, и его работа почти не пострадала. Но дело могло бы обернуться гораздо хуже, чья-то жизнь могла бы подвергнуться опасности. Сегодня этот call-центр службы спасения уже не берет на себя такого риска. Они внедрили всеобъемлющую программу профилактического техобслуживания, которая гарантирует бесперебойную работу их систем. Такой же выбор следует сделать всем менеджерам ЦОДов в наше время, полное перемен.
Любой компании, будь то транснациональная корпорация или малое предприятие со штатом в два человека, необходим офис. Ведь офис, это не только то место, где мы проводим переговоры с партнерами и принимаем клиентов, но и место, где ведется повседневная кропотливая работа сотрудниками компании, направленная на развитие и процветание нашего бизнеса.
Задумайтесь, ведь если из нашей жизни вычесть время, отведенное на сон, то окажется, что большую часть своего времени мы проводим в офисе, выполняя нашу повседневную работу. И ведь никто из нас не хочет провести большую часть своей жизни в сыром и темном подвале. Следовательно, задумываясь о том, чтоб снять офис недорого , необходимо помнить что офис, по сути, является вторым домом для его сотрудников, и наличие исправной инженерной инфраструктуры (вентиляции, электроснабжения, отопления, водоснабжения, подключения к Интернету и т.д.) играет не последнюю роль в обеспечении его устойчивого и успешного функционирования.
«Обеспечение функционирования офиса» - эта фраза, зачастую, фигурирует под номером один в должностных обязанностях офис-менеджера. Давайте же разберемся, что скрывается под этой сухой фразой, и что необходимо обеспечить для организации нормального функционирования офиса:
- обеспечение соблюдения требований противопожарной безопасности;
- обеспечение безопасности персонала;
- обеспечение информационной безопасности;
- обеспечение услуг связи, интернета;
- обеспечение учета и контроля расходов на телефонные переговоры;
- организация работы транспорта;
- обеспечение курьерской связи;
- организация питания сотрудников;
- организация рабочих мест, эргономика;
- обеспечение необходимого уровня освещенности и параметров микроклимата;
- организация производственного контроля;
- организация сервисно-профилактических работ;
- организация проведения профилактического обслуживания и ремонта офисной техники;
- обеспечение наличия необходимых канцелярских принадлежностей и расходных материалов;
- организация перемещения мебели;
- обеспечение вывоза мусора;
- организация уборки помещений;
- организация ведения учета посетителей;
- организация поездок сотрудников (заказ авиа- и железнодорожных билетов для сотрудников офиса), диспетчеризация автотранспорта.
И это далеко не полный список мероприятий, необходимых для успешной работы офиса
Организация и контроль работы офиса – это непрерывный рабочий процесс. Он должен контролироваться на всех этапах, чтобы была уверенность в том, что офис функционирует четко и без сбоев. Но зачастую, далеко не всегда офис-менеджеру под силу обеспечить в полной мере выполнение всех мероприятий, для обеспечения бесперебойной работы офиса. Многие факторы просто неподвластны ему.
Ведь обеспечение бесперебойной работы систем вентиляции, электроснабжения, водоснабжения, отопления и других инженерных систем; обеспечение охраны и пожарной безопасности; содержание в чистоте и исправном состоянии лифтов и мест общего пользования – это те факторы, выполнение которых лежит тяжким грузом на плечах собственника арендуемого офиса. При этом они оказывают немалое влияние на устойчивое функционирование офиса, и как следствие на развитие и процветание бизнеса.
Арендуя офис в офисном центре, обратите особое внимание на то, в каком состоянии содержится здание, и удостоверьтесь в том, что собственник прилагает все усилия для обеспечения комфортной работы Вашего офиса, и только тогда вы сможете быть уверены в плодотворной работе и грядущих успехах Вашего бизнеса.
Для любой компании крайне важна бесперебойная работа ее IT-инфраструктуры, особенно серверов и установленного на них программного обеспечения. Прекращение доступа к Интернет, электронной почте, базам данных и другим приложениям неминуемо приведет к серьезным сбоям в бизнес-процессах компании.
Для обеспечения стабильной работы приложений серверное оборудование должно отвечать высоким требованиям по надежности. Одним из основных методов повышения надежности сервера является резервирование его подсистем путем дублирования компонентов: процессора, оперативной памяти, сетевых подключений, дисковых и твердотельных накопителей, устройств охлаждения, блоков питания. Отказ дублированного компонента не приводит к отказу сервера в целом, но может снизить его производительность. Устранение неисправности обычно выполняется без остановки работы сервера путем "горячей" замены отказавшего компонента.
Однако полное резервирование в рамках традиционной серверной архитектуры невозможно. Такие компоненты сервера как системная плата и контроллер дисков обычно не дублируются. Поэтому их выход из строя будет означать отказ сервера в целом и, как следствие, аварийную остановку всех приложений. Какова вероятность такой ситуации?
Надежность сервера определяется параметром MTBF — средним временем наработки на отказ. MTBF сервера можно вычислить теоретически — на основании известных значений MTBF серверных компонентов. С помощью данного метода мы рассчитали MTBF типового сервера и получили значение, равное 10 годам (детали расчета). Для такого сервера вероятность выхода из строя в течение одного года будет равна 10%.
Согласно статистике нашего сервисного центра серверы Team имеют среднее время наработки на отказ 25 лет, коэффициент готовности 99,99% и вероятность выхода из строя в течение одного года около 4%. При этом в отличие от "теоретического" расчета наша статистика учитывает любые отказы, в том числе и отказы дублированных компонентов, которые не приводят к отказу сервера в целом.
Очевидно, что столь высокие показатели надежности вполне достаточны для обеспечения устойчивой работы серверных приложений и соответствуют потребностям большинства компаний малого и среднего бизнеса.
Однако для некоторых компаний внеплановая остановка бизнес-приложений (пусть даже очень маловероятная) неприемлема. Например, одним из клиентов нашей компании является предприятие непрерывного цикла с численностью работников 150 человек. Производственный процесс на предприятии управляется при помощи специализированного серверного приложения. Остановка этой программы означает остановку производства. Восстановление работоспособности приложения после аппаратного или программного сбоя может занять несколько часов и на протяжении этого времени производство будет простаивать. Поэтому требуется обеспечить гарантированную непрерывность работы этого приложения как необходимое условие непрерывности всего бизнес-процесса.
Переход на виртуальную платформу VMware позволяет решить эту задачу.
Предлагаемое решение основано на использовании кластера двух (или более) серверов с общей системой хранения. В таком кластере все компоненты (в том числе компоненты системы хранения) продублированы. Восстановление работы приложений в случае отказа одного из серверов обеспечивается средствами виртуализации.
В штатном режиме на каждом сервере работает свой набор приложений, каждое приложение — в отдельной виртуальной машине. Все приложения изолированы друг от друга и не влияют на работу других приложений. Виртуальные машины и данные, с которыми они работают, хранятся на общем дисковом массиве, доступ к которому имеют оба сервера. Распределение виртуальных машин по серверам изначально задается администратором. Им же для каждой виртуальной машины выделяется часть аппаратных ресурсов сервера, при этом коэффициент загрузки каждого сервера может достигать 70-80%.
Непрерывность работы приложений обеспечивается средствами виртуальной платформы, которые осуществляют постоянный мониторинг виртуальных машин. В случае остановки виртуальной машины из-за отказа сервера она автоматически перезапустится на другом сервере. После устранения причины отказа и включения сервера виртуальные машины автоматически вернутся на "свой" сервер без прерывания работы.
Данное решение позволяет выполнять плановые работы по техническому обслуживанию серверов без остановки приложений. Перед выключением сервера его приложения "переезжают" на другой сервер, а после завершения работ возвращаются обратно.
Важным достоинством данного решения является его универсальность, поскольку оно подходит для любых приложений и не накладывает практически никаких ограничений на тип гостевых операционных систем виртуальных машин. Этим оно выгодно отличается от службы кластеров Microsoft Windows Server. Другими преимуществами решения являются более эффективное использование аппаратных ресурсов серверов, а также простота внедрения и администрирования.
Состав решения
Решение по обеспечению непрерывной работы серверных приложений на виртуальной платформе VMware включает следующие компоненты:
- Два (или более) сервера Team . Все серверы Team совместимы с платформой VMware.
- Дисковый RAID-массив с полным резервированием подсистем.
- VMware Essentials Plus Kit в качестве платформы виртуализации.
- Лицензии на операционные системы в соответствии с количеством виртуальных машин.
- Необходимые пользователю серверные приложения.
В рамках внедрения данного решения наша компания готова выполнить следующие работы:
- Подбор конфигурации серверов с требуемым уровнем производительности.
- Подбор системы хранения.
- Поставку серверов, системы хранения и другого необходимого оборудования.
- Поставку программного обеспечения.
- Монтаж и подключение оборудования.
- Установку и настройку платформы виртуализации.
- Установку и настройку виртуальных машин, операционных систем и приложений.
- Тестирование системы и ввод в эксплуатацию.
- Сопровождение в рамках гарантийного обслуживания и, по желанию, по договору аутсорсинга.
В составе решения мы бесплатно предоставим восемь часов работы сертифицированного специалиста VMware и Microsoft для консультаций, обучения и работ по внедрению решения.